The next 100 vendors should not require the next 10 analysts.
Vendor risk teams do not have a people problem. They have a work problem.
The volume of work is growing faster than the teams responsible for it. More vendors. More assessments. More evidence to review. More regulatory pressure. More monitoring signals. More issues to chase. More decisions to document.
For years, the answer was simple: add people. Hire another analyst. Bring in managed services. Pay someone else to collect the documents, send the reminders, review the questionnaires, and keep the process moving.
That helps for a while.
But it does not fix the operating model.
If every new vendor creates another manual intake review, another evidence chase, another questionnaire cycle, another remediation follow-up, and another audit trail to rebuild later, the program still scales one body at a time.
That is the problem.
You do not scale TPRM by adding more hands to the backlog. You scale it by removing the handoffs that create the backlog in the first place.
TPRM work is scaling faster than the team
Third-party risk has moved from periodic vendor review to continuous oversight.
Security and risk teams are no longer being asked to assess vendors once a year and move on. They need to know which vendors matter, what systems they touch, what evidence supports the risk decision, what has changed since the last review, whether a new signal requires action, and how the response was documented.
That is a bigger job.
It is also happening under more scrutiny. DORA, NIS2, SEC cyber disclosure rules, NYDFS, and other regulatory requirements are pushing organizations toward stronger third-party oversight, faster response, and better evidence. At the same time, vendor ecosystems are expanding and third-party incidents are becoming harder to ignore.
The result is familiar to anyone running a lean TPRM program: the business keeps adding vendors, the risk surface keeps expanding, and the team is expected to keep pace without a matching increase in headcount.
That is where the old model starts to break.
Not because teams are careless. Not because analysts are slow. Not because the work is unimportant.
Because too much of the work still depends on manual coordination.
Manual work hides inside the process
A vendor enters the business. Someone has to decide what type of review is needed. Someone has to route the request. Someone has to determine the tier. Someone has to send the right questionnaire. Someone has to find the vendor’s security documentation. Someone has to chase missing evidence. Someone has to read the SOC 2, ISO certificate, policy, or completed questionnaire. Someone has to decide whether the answer is supported. Someone has to create an issue. Someone has to follow up. Someone has to document the decision.
That is one vendor.
Now multiply it by hundreds.
The problem is not one task. The problem is the chain of tasks. Each handoff adds time. Each manual step creates another place for context to get lost. Each disconnected system creates another place where the evidence separates from the decision it supported.
That is how teams end up with risk work spread across spreadsheets, inboxes, portals, ticketing systems, monitoring dashboards, and shared drives.
The tool may show the status. The work still depends on a person to keep the program moving.
That is not scale.
That is manual effort with better screens.
Managed services add capacity. They do not always change the cost curve.
Managed services can be useful. For overloaded teams, outside help can clear assessments, collect documents, and move reviews forward. There are times when that capacity matters.
But the bigger question is not whether services can help with the work.
The bigger question is what happens as the portfolio grows.
What does the next 100 vendors cost?
If every new vendor means another engagement, another document collection fee, another manual review, or another services dependency, the cost curve has not changed. The organization may have moved work outside the team, but it has not reduced how much work the program requires.
That is the difference between staffing the process and automating the operation.
One model adds labor around the work.
The other changes how the work gets done.
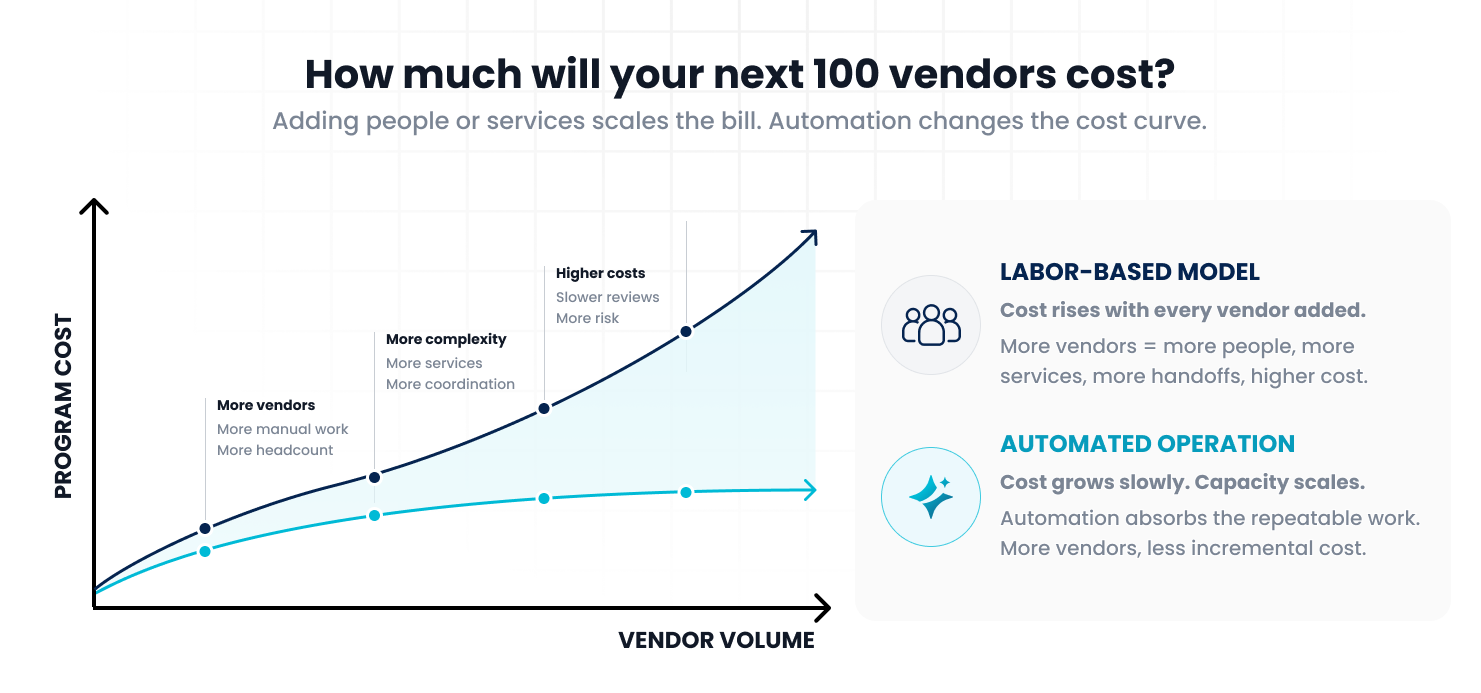
For TPRM teams under pressure to manage more vendors with the same team, that difference matters. A services-heavy model can help a team survive growth. A platform model should help the team absorb growth.
The goal is not just more capacity.
The goal is more vendors, more coverage, and better documentation without a matching increase in people, spend, and coordination.
The platform should do the repeatable work
A modern TPRM platform should not just store vendor records or push questionnaires from one queue to another. It should work the risk before an analyst has to touch it.
That starts at intake.
Low-risk vendors should not require the same attention as critical vendors. The platform should route requests based on the rules the team has already defined. A low-risk vendor can move through a lighter path. A high-risk or critical vendor can receive the right assessment automatically. The analyst should not have to make every routing decision by hand.
It continues with evidence.
The document chase is one of the places TPRM scale dies. If a vendor has a trust center, a published security profile, or reusable documentation already available, the platform should help find it and bring it into the review. Teams should not have to start every assessment by hunting for the same artifacts.
It continues through assessment review.
AI can read SOC 2 reports, ISO certificates, policies, and questionnaires. It can map evidence to controls, identify where answers are supported, surface gaps, and explain what it found. That does not remove human judgment. It gives analysts a better starting point, with citations and confidence scores attached to the output.
It continues after the assessment.
Monitoring should not stop at an alert. A signal should connect to the vendor record, the known context, the issue workflow, the remediation path, and the decision trail. Otherwise, the dashboard updates and the real work begins somewhere else.
That is the shift Whistic is built around.
Automation and agents do the work. Humans review and decide.
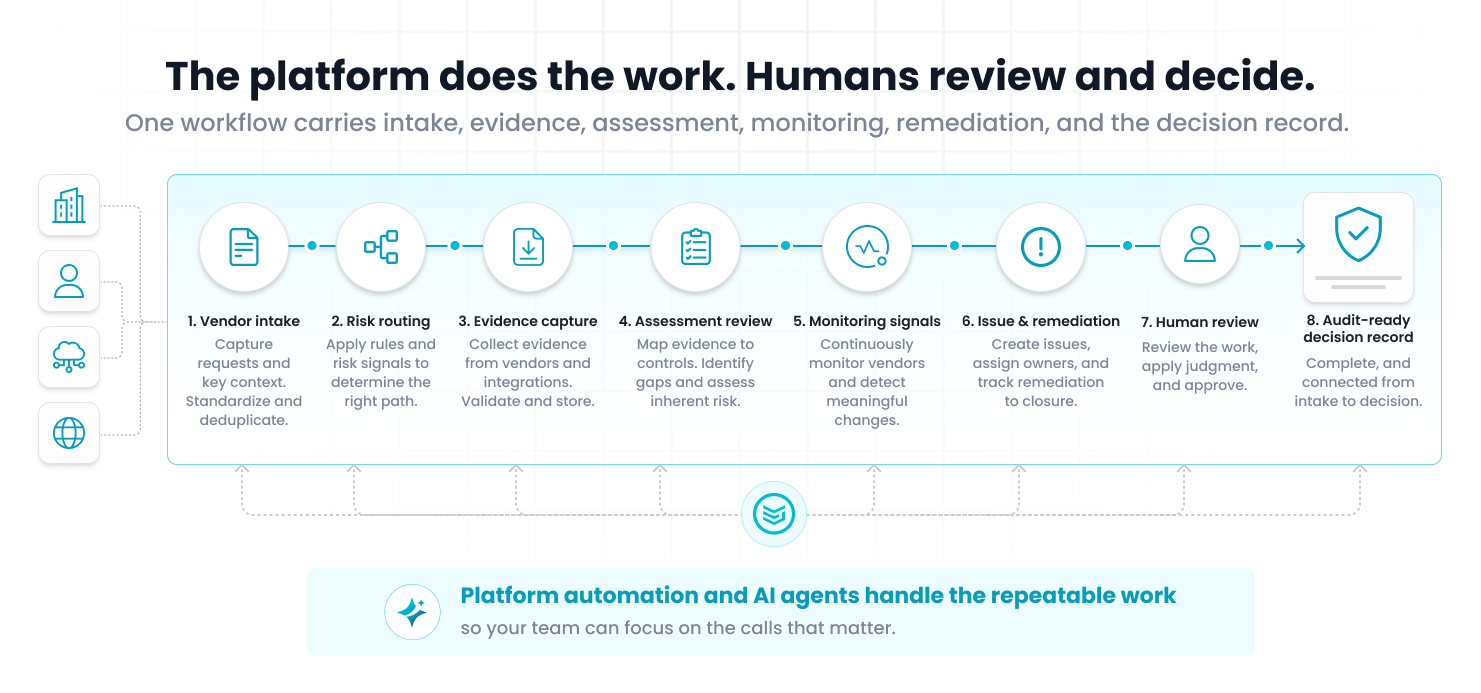
Scale requires one workflow, not five.
A lot of TPRM programs look connected from a systems perspective. Intake is in one place. Assessments are in another. Monitoring lives in a dashboard. Remediation happens in tickets. Evidence is stored in a repository. Reporting happens later.
Some of those systems may even be integrated.
But integration is not the same as operation.
Moving data from one place to another does not guarantee the work moves with it. The harder question is whether the vendor context, evidence, issue history, reviewer notes, monitoring signals, and final decision stay connected as the work progresses.
That is where scale is won or lost.
When every step lives in a different place, the team spends too much time reconstructing the story. What changed? Who reviewed it? What evidence supported the answer? What decision was made? What still needs follow-up? What do we show the auditor?
A scalable TPRM program should not have to rebuild that record after the fact.
The record should be created as the work happens.
That is what audit-ready by default means. Not a separate scramble. Not another spreadsheet. Not screenshots collected at the end.
A timestamped, evidence-backed trail that follows the work from intake to assessment to monitoring to remediation to decision.
Automation should protect the decision, not just speed up the task
Speed matters. Faster assessments help the business move. Faster evidence review helps analysts focus. Faster routing reduces bottlenecks.
But speed alone is not the outcome.
The outcome is a risk decision the team can stand behind.
That is why automation in TPRM has to do more than accelerate tasks. It has to preserve the proof behind the decision. If AI summarizes a document, the source should be cited. If a questionnaire answer is suggested, the evidence should stay attached. If a monitoring signal triggers an action, the response should be logged. If a control is tested, the evidence should be captured. If a risk is accepted, the rationale should be visible later.
Otherwise the team may move faster, but it still has to prove what happened manually.
That is not enough for the way vendor risk is changing.
Regulators, auditors, customers, and boards are not just asking whether a review was completed. They want to know what was reviewed, what changed, what the team did, and why the decision was reasonable.
The platform should help answer those questions without sending the team back through email threads and shared drives.
The business case is capacity without a hiring requisition
This is the executive conversation.
CISOs, GRC leaders, and procurement teams are not just buying another vendor risk tool. They are buying capacity.
They need to know whether the same team can support more vendors, broader coverage, continuous monitoring, stronger evidence requirements, and faster business intake without adding headcount at the same rate.
That is the platform case for Whistic.
Whistic helps security and risk teams assess, monitor, and manage vendor risk in one workflow. Agentic AI reads vendor evidence, maps it to controls, cites the source, and gives teams confidence-scored answers they can review. Vendor Monitoring keeps teams aware of changes between assessments. Compliance creates timestamped evidence for internal controls. Trust Center Exchange gives teams access to more than 100,000 vendor profiles so they can reuse what already exists instead of sending another questionnaire.
The point is not to replace the team.
The point is to stop wasting the team on work the platform can do first.
A Fortune 200 financial services customer saw more than $450,000 in annual savings, 80% faster assessments, and an 87% improvement in turnaround time, reducing assessment cycles from eight weeks to one week.
That is what scale should look like.
Not more status tracking.
More work completed before the analyst has to start from zero.
The next 100 vendors should cost less to manage
Every risk leader should ask a simple question before choosing a TPRM model:
What happens when the portfolio grows?
If the answer is more analysts, more services engagements, more manual reviews, more document chase, and more disconnected evidence, the program is still scaling the old way.
It may work for the next quarter. It may even work for the next budget cycle.
But it will not hold as vendor volume grows, regulatory pressure increases, and the business expects faster decisions.
The next 100 vendors should not require the same amount of manual work as the last 100.
That is the promise of an automated TPRM operation.
Route the intake. Find the evidence. Read the documents. Map the controls. Surface the gaps. Trigger the workflow. Capture the record. Keep the proof attached.
Let the platform do the repeatable work.
Let the team make the calls.
Grow the program, not the services bill
TPRM teams are under pressure from every direction. More vendors. More scrutiny. More signals. More evidence. More decisions.
The answer cannot be to keep adding manual work to an already overloaded process.
And it cannot be to assume every increase in vendor volume requires a matching increase in headcount or services spend.
That is how the backlog wins.
The better question is: what work should already be done before an analyst opens the file?
For modern TPRM, that is where scale comes from. Automated intake. Evidence capture. AI-assisted assessment review. Continuous monitoring. Connected remediation. Audit-ready decision records.
Not five workflows.
One operation.
You can grow your services bill.
Or you can grow your program.